



本文经自动驾驶之心公众号授权转载,转载请联系出处。
原标题:DifFlow3D: Toward Robust Uncertainty-Aware Scene Flow Estimation with Iterative Diffusion-Based Refinement
论文链接:https://arxiv.org/pdf/2311.17456.pdf
代码链接:https://github.com/IRMVLab/DifFlow3D
作者单位:上海交通大学 剑桥大学 浙江大学 鉴智机器人

论文思路:
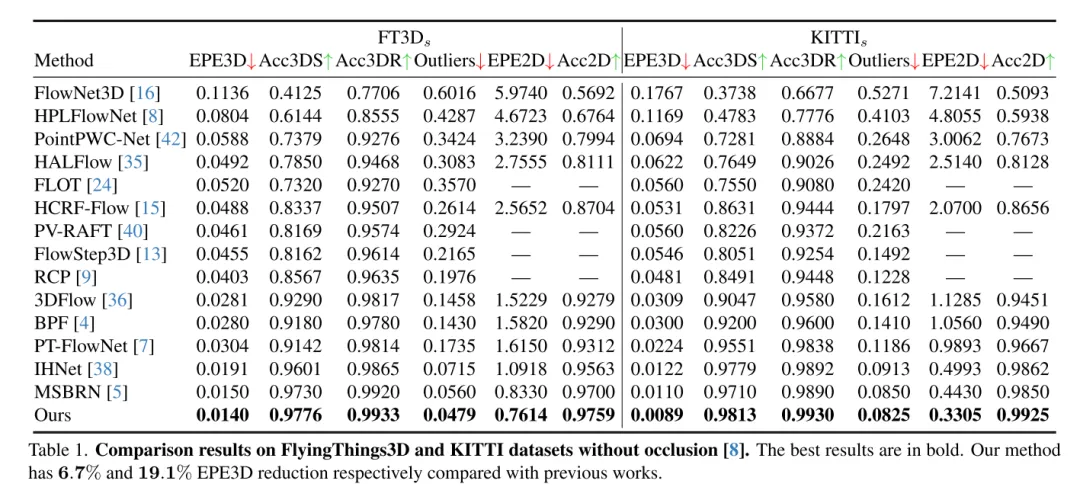
场景流估计旨在预测动态场景中每个点的3D位移变化,是计算机视觉领域的一个基础任务。然则,以往的工作常常受到局部约束搜索范围引起的不可靠相关性的困扰,并且在从粗到细的结构中积累不准确性。为了缓解这些问题,本文提出了一种新颖的不确定性感知场景流估计网络(DifFlow3D),该网络采用了扩散概率模型。设计了迭代扩散式细化(Iterative diffusion-based refinement)来增强相关性的鲁棒性,并对困难情况(比如动态、噪声输入、重复模式等)具有较强的适应性。为了限制生成的多样性,本文的扩散模型中利用了三个关键的与流相关的特征作为条件。4,本文还在扩散中开发了一个不确定性估计模块,以评估估计场景流的可靠性。本文的 DifFlow3D 在 FlyingThings3D 和 KITTI 2015 数据集上分别实现了6.7%和19.1%的三维端点误差(EPE3D)降低,并在KITTI数据集上实现了前所未有的毫米级精度(EPE3D为0.0089米)。另外,本文的基于扩散的细化范式可以作为一个即插即用的模块,轻松集成到现有的场景流网络中,显著提高它们的估计精度。
主要贡献:
为了实现鲁棒的场景流估计,本文提出了一种新颖的即插即用型基于扩散的细化流程。据本文所知,这是首次在场景流任务中利用扩散概率模型。
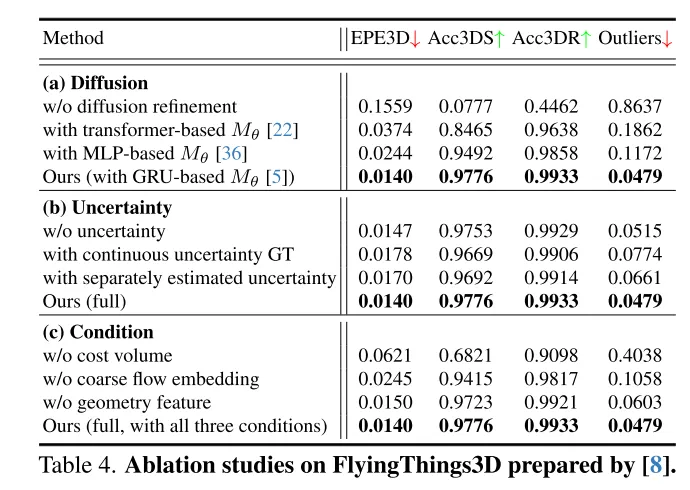
本文通过结合粗流嵌入、几何编码和跨帧成本体积(coarse flow embeddings, geometry encoding, cross-frame cost volume),设计了强有力的条件引导来控制生成的多样性。
为了评估本文估计流的可靠性并识别不准确的点匹配,本文还在本文的扩散模型中引入了每个点的不确定性估计。
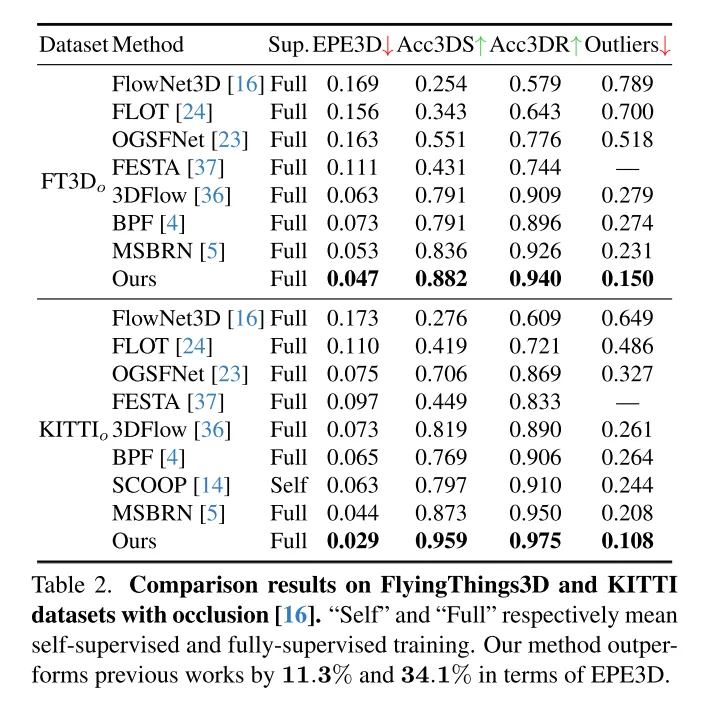
本文的方法在 FlyingThings3D 和 KITTI 数据集上均优于所有现有方法。特别是,本文的 DifFlow3D 首次在 KITTI 数据集上实现了毫米级的端点误差(EPE3D)。与以往的工作相比,本文的方法对于具有挑战性的情况具有更强的鲁棒性,比如噪声输入、动态变化等。
网络设计:
场景流作为计算机视觉中的一项基础任务,指的是从连续的图像或点云中估计出的三维运动场。它为动态场景的低层次感知提供了信息,并且有着各种下游应用,比如自动驾驶[21]、姿态估计[9]和运动分割[1]。早期的工作集中在使用立体[12]或RGB-D图像[10]作为输入。随着3D传感器,比如激光雷达的日益普及,近期的工作通常直接以点云作为输入。
作为开创性的工作,FlowNet3D[16]使用 PointNet++[25] 提取层次化特征,然后迭代回归场景流。PointPWC[42] 通过金字塔、变形和成本体积结构[31]进一步改进了它。HALFlow[35] 跟随它们,并引入了注意力机制以获得更好的流嵌入。然则,这些基于回归的工作通常遭受不可靠的相关性和局部最优问题[17]。原因主要有两个方面:(1)在他们的网络中,使用K最近邻(KNN)来搜索点对应关系,这并不能考虑到正确但距离较远的点对,也存在匹配噪声[7]。(2)另一个潜在问题来自于以往工作[16, 35, 36, 42]中广泛使用的粗到细结构。基本上,最初的流在最粗糙的层上估计,然后在更高分辨率中迭代细化。然则,流细化的性能高度依赖于初始粗流的可靠性,因为后续的细化通常受限于初始化周围的小的空间范围内。
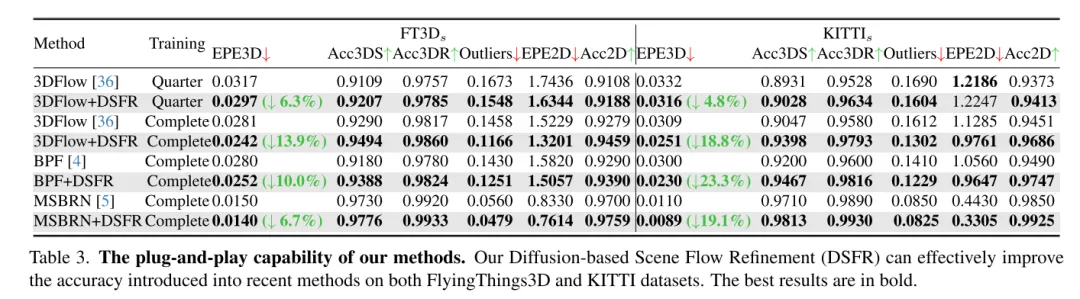
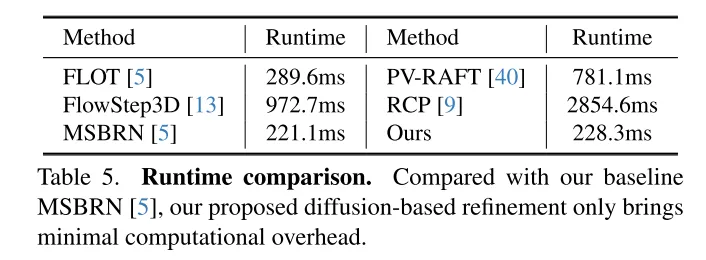
为了解决不可靠性的问题,3DFlow[36] 设计了一个 all-to-all 的点收集模块,并加入了反向验证。类似地,Bi-PointFlowNet[4] 及其扩展MSBRN[5] 提出了一个双向网络,具有前向-后向相关性。IHNet[38] 利用一个带有高分辨率引导和重采样方案的循环网络。然则,这些网络大多因其双向关联或循环迭代而在计算成本上遇到了困难。本文发现扩散模型也可以增强相关性的可靠性和对匹配噪声的韧性,这得益于其去噪本质(如图1所示)。受到[30]中的发现的启发,即注入随机噪声有助于跳出局部最优,本文用概率扩散模型重新构建了确定性流回归任务(deterministic flow regression task),如图2所示。4,本文的方法可以作为一个即插即用的模块服务于先前的场景流网络,这种方法更为通用,并且几乎不增加计算成本(第4.5节)。
然则,在本文的任务中利用生成模型是相当具有挑战性的,因为扩散模型固有的生成多样性。与需要多样化输出样本的点云生成任务不同,场景流预测是一个确定性任务,它计算精确的每点运动向量。为了解决这个问题,本文利用强条件信息来限制多样性,并有效控制生成的流。具体来说,首先初始化一个粗糙的稀疏场景流,然后通过扩散迭代生成流残差(flow residuals)。在每个基于扩散的细化层中,本文利用粗流嵌入、成本体积和几何编码作为条件。在这种情况下,扩散被应用于实际学习从条件输入到流残差的概率映射。
4,先前的工作很少探索场景流估计的置信度和可靠性。然则,如图1所示,在噪声、动态变化、小物体和重复模式的情况下,密集流匹配容易出错。所以,了解每个估计的点对应关系是否可靠是非常重要的。受到最近在光流任务中不确定性估计成功的启发[33],本文在扩散模型中提出了逐点不确定性,以评估本文的场景流估计的可靠性。
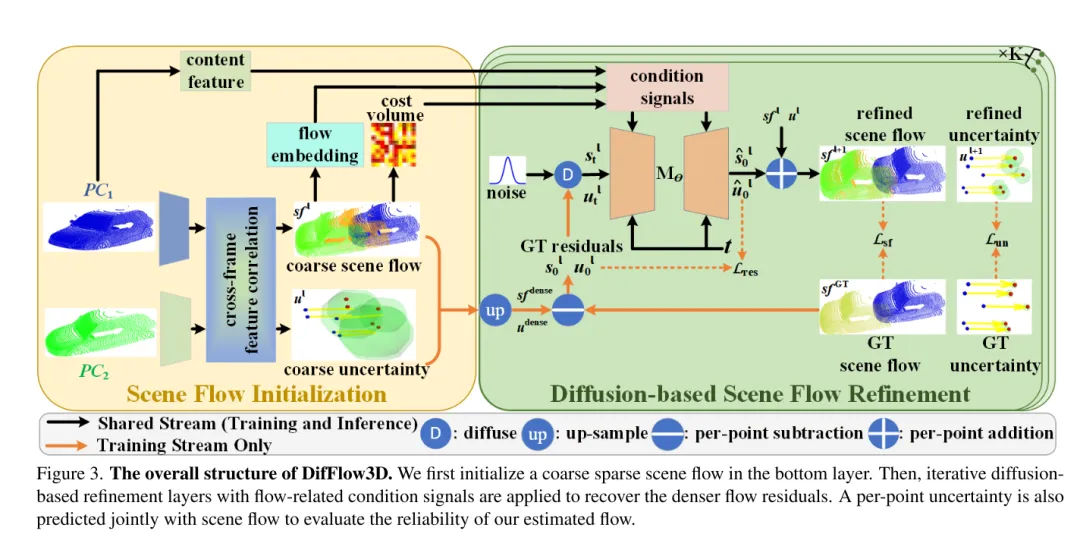
图3。DifFlow3D 的总体结构。本文首先在 bottom layer 初始化一个粗糙的稀疏场景流。随后,将迭代扩散式细化层与流相关的条件信号结合使用,以恢复更密集的流残差。为了评估本文估计的流的可靠性,还将与场景流一起联合预测每个点的不确定性。
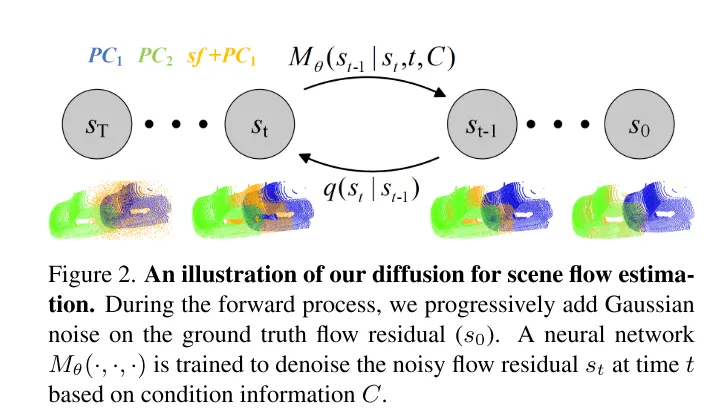
图2。本文用于场景流估计的扩散过程示意图。
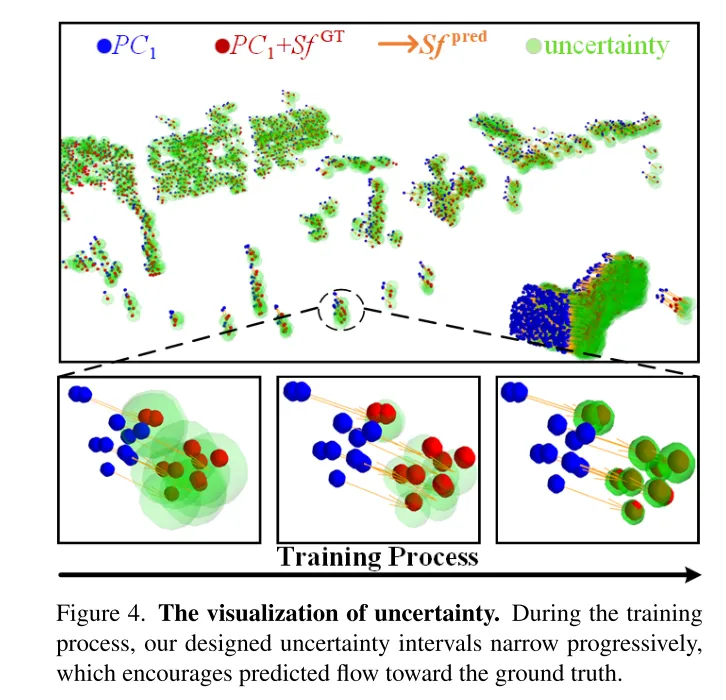
图4。不确定性的可视化。在训练过程中,本文设计的不确定性区间逐渐缩小,这促使预测的流向真实值靠拢。
实验结果:
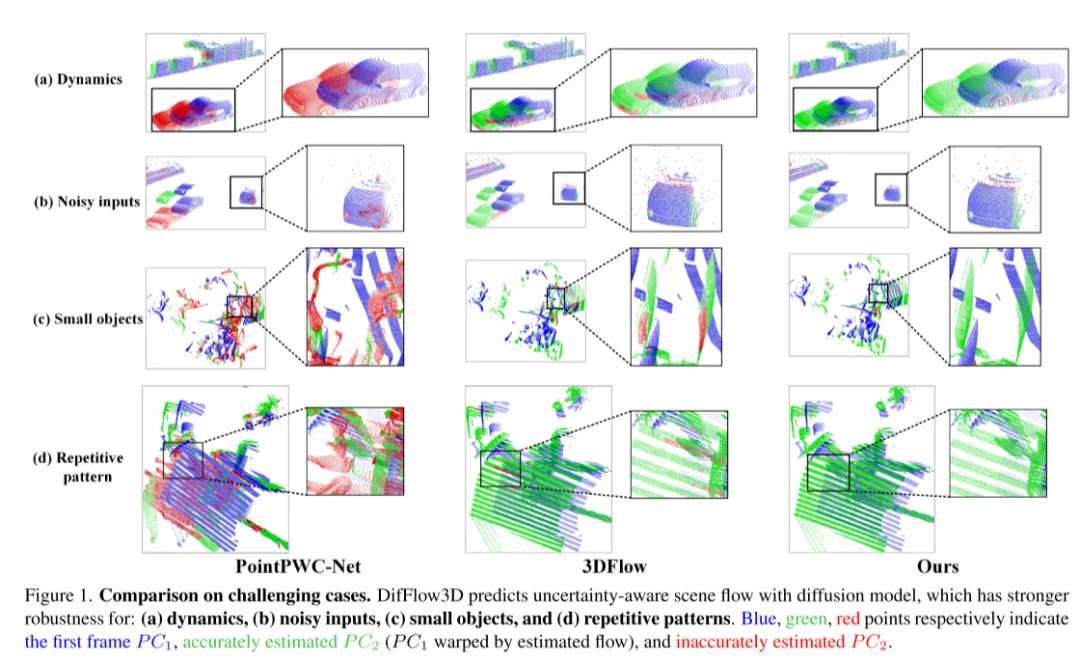
图1。在具有挑战性的情况下的比较。DifFlow3D 使用扩散模型预测具有不确定性感知的场景流,该模型对以下情况具有更强的鲁棒性:(a)动态变化,(b)噪声干扰的输入,(c)小物体,以及(d)重复模式。
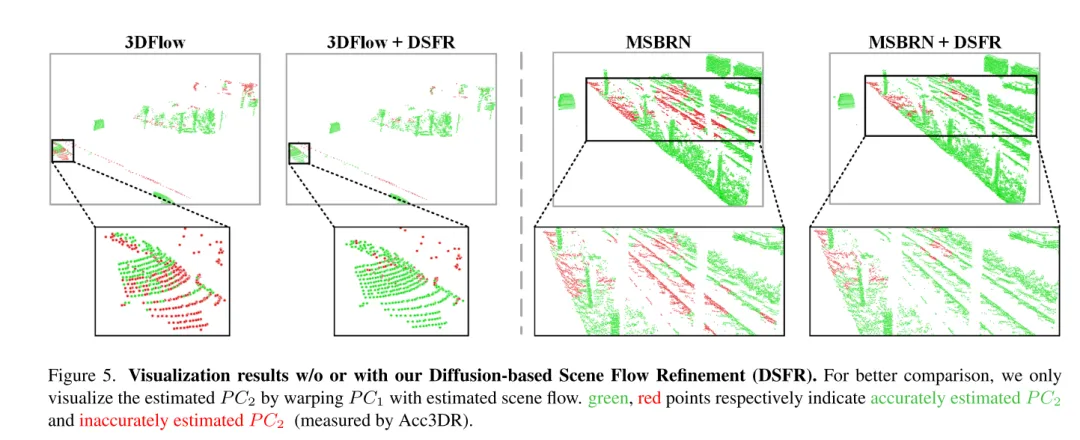
图 5. 未使用或使用基于扩散的场景流细化 (DSFR) 的可视化结果。
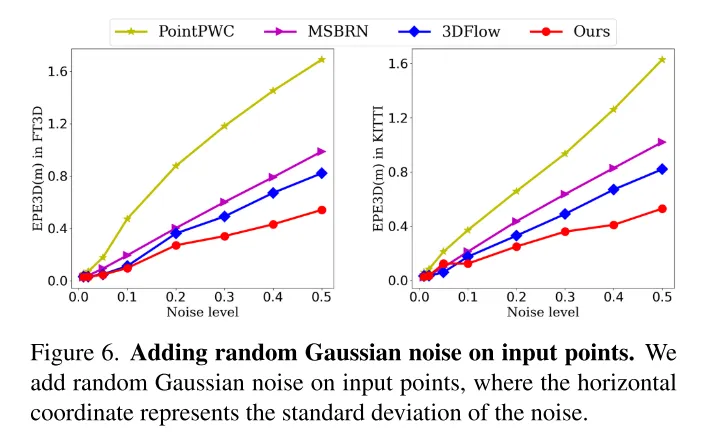
图6。在输入点上添加随机高斯噪声。
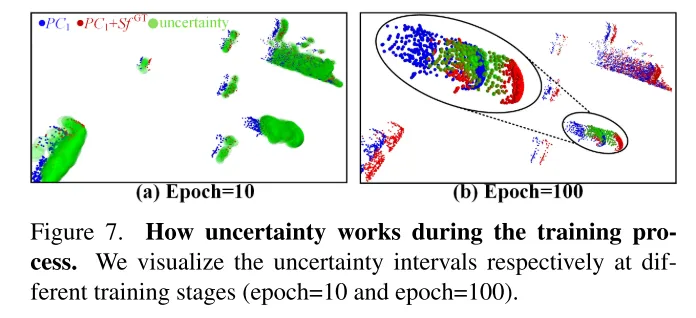
图7。不确定性在训练过程中的作用。本文分别在不同的训练阶段(第10轮和第100轮)可视化了不确定性区间。
总结:
本文创新性地提出了一个基于扩散的场景流细化网络,该网络能够感知估计的不确定性。本文采用多尺度扩散细化来生成细粒度的密集流残差。为了提高估计的鲁棒性,本文还引入了与场景流一起联合生成的逐点不确定性。广泛的实验表明了本文的 DifFlow3D 的优越性和泛化能力。值得注意的是,本文的基于扩散的细化可以作为即插即用模块应用于以往的工作,并为未来的研究提供新的启示。
引用:
Liu J, Wang G, Ye W, et al. DifFlow3D: Toward Robust Uncertainty-Aware Scene Flow Estimation with Diffusion Model[J]. arXiv preprint arXiv:2311.17456, 2023.

